Implementation
Implementation of the Medical LLM
Model Repository
The fine-tuned medical LLM is available on Hugging Face: mlai-dante/medical-llm
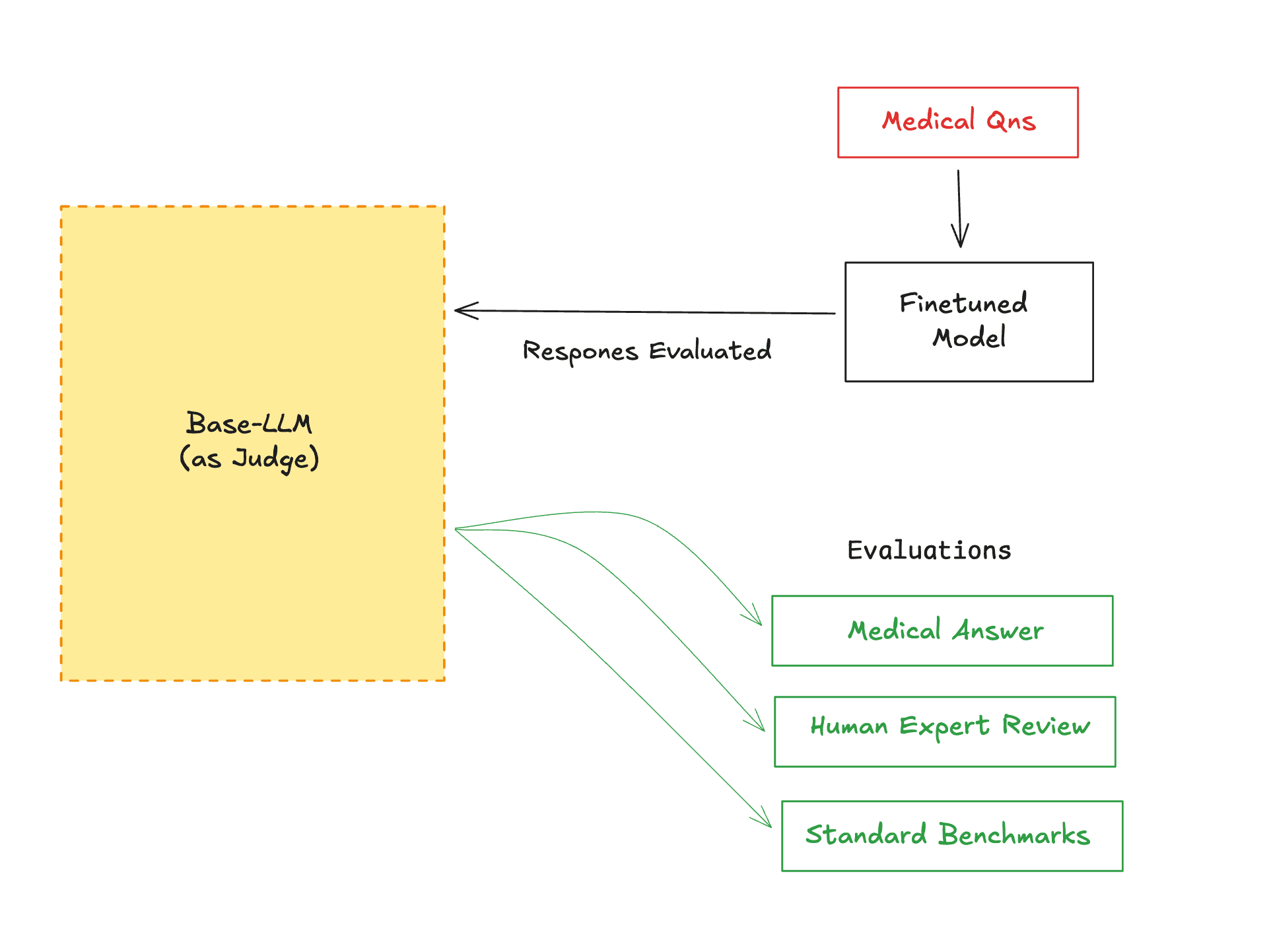
You can load and use the model with the PEFT library. The model is built on Meta's Llama 3.1 8B and fine-tuned using LoRA adapters for efficient medical terminology understanding.
Setup
For this project, I set up a fine-tuning pipeline using a specialized medical dataset and a powerful language model:
- Dataset: I used the gamino/wiki_medical_terms dataset from Hugging Face. This dataset contains a wide range of medical terms and definitions, making it ideal for training models to understand and generate medical language.
- Model: The base model for fine-tuning was the Llama-3.1 8B, a state-of-the-art large language model.
- Fine-tuning API: Fine-tuning was performed using the Thinking Machine Tinker API, which streamlines the process of adapting large models to domain-specific datasets.
- Technique: The fine-tuning process used the LoRA (Low-Rank Adaptation) technique with a rank of 32, enabling efficient adaptation of the large model while reducing computational requirements.
This implementation allows the Llama-3.1 8B model to better understand and generate text related to medical terminology, improving its performance on healthcare and biomedical tasks.